Unter Datenmodellierung wird bei Datenbanken das Erstellen des Datenbankschemas verstanden
Das Datenbankschema legt fest, welche Daten in der Datenbank gespeichert werden und welche Beziehungen sie zueinander haben
Das konzeptuelle Datenbankschema ist eine abstrakte, formale Beschreibung und Darstellung des entsprechen-den Ausschnitts der realen Welt
Das logische Datenbankschema wird aus dem konzep-tuellen Datenbankschema entwickelt und erweitert das Modell um datentechnische Angaben, wie z. B.
Feldformate
Beim physischen Datenbankschema werden zur Erstellung der Datenbank alle Angaben in der entsprechenden Syntax des verwendeten DBMS
(Datenbankmanagementsystem) formuliert
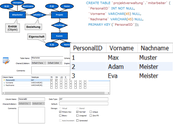
Das Entity-Relationship-Modell (kurz ER-Modell oder ERM) wird für den Entwurf von relationalen Datenbanken im Rahmen der
semantischen Datenmodellierung verwendet
Bei der Modellierung werden von den individuellen realen Objekten allgemeingültige Typen, die Entitätstypen, abgeleitet
Aus gleichartigen Eigenschaften der individuellen Entitäten werden bei der Typisierung die Attribute der Entitätstypen
Attribute oder Attributskombinationen, mit denen Entitäten eindeutig identifiziert werden können, werden Primärschlüssel genannt
Mit Hilfe von Beziehungen werden Zusammenhänge zwischen Entitäten definiert und aus gleichartigen Beziehungen werden
Beziehungstypen abgeleitet
Die Kardinalität legt bei Beziehungstypen fest, mit wie vielen Entitäten eines Entitätstyps eine Entität eines anderen Entitätstyps eine Beziehung eingehen
kann
Die im Rahmen des ER-Modells definierten Entitätstypen, Attribute und Beziehungstypen lassen sich mit Hilfe von ER-Diagrammen grafisch darstellen
Mit Hilfe der Normalisierung werden in relationalen Datenbankschemata Redundanzen vermieden oder beseitigt
Redundanz bedeutet, dass Informationen mehrfach vorhanden sind
Bei Datenbanken führt Redundanz zu erhöhtem Speicherbedarf und Inkonsistenzen
Bei der Normalisierung werden Attribute (Spalten) so auf mehrere Relationen (Tabellen) aufgeteilt, dass keine oder weniger redundanten Informationen
gespeichert werden
Der Prozess der Normalisierung erfolgt in mehreren Stufen, die als Normalformen bezeichnet werden
In den meisten Fällen ist die dritte Normalform ausreichend, die eine gute Ausgewogenheit zwischen Redundanz, Performance und Flexibilität bietet
Die referentielle Integrität definiert Regeln, zur Erreichung und Sicherung der Integrität von Daten in Datenbanken
Die RI-Regeln definieren Bedingungen, wie Datensätze in Datenbanken eingefügt und gelöscht werden dürfen, damit die Integrität der Daten erhalten bleibt
Ein Datensatz mit einem Fremdschlüssel darf nur dann in eine Tabelle eingefügt werden, wenn in der referenzierten Tabelle ein Datensatz mit einem
passenden Schlüssel existiert
Ein Datensatz, dessen Schlüssel in einer anderen Tabelle als Fremdschlüssel verwendet wird darf nicht gelöscht und sein Schlüssel nicht verändert werden
Die technische Umsetzung der referentiellen Integrität erfolgt über Fremdschlüssel
Das DBMS prüft mit Hilfe von Schlüsseln, dass beim Einfügen und Löschen von Datensätzen nur Verweise auf existierende Datensätze entstehen bzw. bestehen
bleiben
Als Transaktion wird in der Informatik eine Abfolge von Teilaktionen bezeichnet, die entweder fehlerfrei und vollständig oder gar nicht
durchgeführt wird
Tritt bei einer Teilaktion einer Transaktion ein Fehler auf, muss die Transaktion abgebrochen und alle bisherigen Änderungen rückgängig gemacht werden
(Rollback)
Transaktionen verhindern, dass in Datenbanken ein inkonsistenter Zustand entsteht, selbst wenn bei der Durchführung von Aktionen Fehler auftreten
In der Informatik wurden vier Eigenschaften definiert, die Transaktionen haben müssen: Atomarität, Konsistenz,
Isolation und Dauerhaftigkeit (ACID-Eigenschaften)
Werden bei MySQL SQL-Anweisungen zwischen „START TRNSACTION“ und „COMMIT“ ausgeführt, werden sie erst nach „COMMIT“ fest in die Datenbank geschrieben
Tritt ein Fehler bei einer SQL-Anweisung innerhalb einer Transaktion auf, können alle SQL-Anweisungen nach „START TRANSACTION“ mit „ROLLBACK“ wieder
zurückgesetzt werden
MySQL ist eines der weltweit am weitesten verbreiteten relationalen Datenbankmanagementsysteme
MySQL gibt es als kostenlose Open-Source-Software unter der GPL-Lizenz und als kostenpflichtige proprietäre Software mit zusätzlichen Tools (u. a. Monitoring und Backup) und
24x7 Support
MySQL ist für die Betriebssysteme Windows, Linux, macOS und verschiedene Unix-Varianten verfügbar und bietet zahlreiche Schnittstellen (API‘s) für
Programmier-sprachen wie z. B. Java, .NET oder PHP
MySQL bietet mehrere verschiedene Speicherengines an, die für das effektive Speichern und Abfragen von Daten zuständig sind
MySQL bietet verschiedene Verfahren zur Partitionierung an, mit denen Daten aufgeteilt und separat gespeichert werden können
Um alle SQL-Anweisungen möglichst performant zu bearbeiten, verwendet MySQL den Query-Cache und den Optimizer
Zur Verwaltung der MySQL-Datenbanken können der MySQL-Kommandozeilen-Client oder die MySQL-Workbench verwendet werden, sowie Werkzeuge
anderer Hersteller, wie z. B. Heidi-SQL oder PHPMyAdmin
MySQL gibt es neben Windows auch für Linux, MacOS und weitere Betriebssysteme
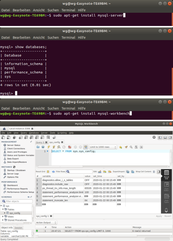
Auf Ubuntu wird der MySQL-Datenbankserver und die MySQL-Workbench mit zwei getrennten Paketen installiert
Der MySQL-Server kann unter Ubuntu aus den Paket-quellen mit dem Paketmanagment-System APT wie folgt installiert werden: sudo apt-get install mysql-server
Die Konfiguration von MySQL erfolgt über die Datei „mysqld.cnf“ im Verzeichnis „etc/mysql/mysql.conf.d/“
Die MySQL-Workbench kann unter Ubuntu aus den Paketquellen mit dem Paketmanagment-System APT wie folgt installiert werden: sudo apt-get install mysql-workbench
Der MySQL-Kommandozeilen-Client „mysql“ ist ein einfaches kommandozeilen-basiertes Werkzeug zur Bedienung eines MySQL-Servers mit Hilfe von SQL-Anweisungen
Der MySQL-Kommandozeilen-Client kann aus der Betriebssystem-Shell wie folgt gestartet werden: mysql -u root -h localhost -p
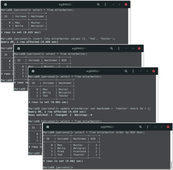
Ein Befehl besteht aus einer SQL-Anweisung, die durch ein Semikolon beendet wird
SQL ist nicht „case-sensitive“, was bedeutet, dass Groß- und Kleinschreibung keine Rolle spielt
Mehrere Abfragen in einem Befehl werden durch Komma getrennt
Mit „\c“ kann die aktuelle Eingabe beendet werden
Mit „exit“ kann der MySQL-Kommandozeilen-Client beendet werden
Mit „INSERT INTOtabellenname(spalte1,spalte2, …)VALUES (wert1,wert2,
...)“ können Datensätze einer Tabelle hinzugefügt werden
Mit „DELETE FROMtabellennameWHEREspaltenname=wert“ können einzelne Datensätze gelöscht werden
Mit „SELECT * FROMtabellenname“werdenalle Datensätze einer Tabelle angezeigt
Mit „SELECT spaltenname1, spaltenname2, ... FROM tabellenname“ werden bestimmte Spalten einer Tabelle angezeigt
Mit „SELECT * FROMtabellennameWHERE spaltenname = wert“ werden nur dieDatensätze angezeigt, bei denenin einerbestimmten
Spalte ein definierbarer Wert steht
Mit „SELECT * FROMtabellennameORDER BYspaltenname“ werden die Datensätze vor der Ausgabe aufsteigend sortiert
Die MySQL-Workbench ist eine grafische Datenbank-Verwaltungssoftware zur Modellierung, Erstellung und Bearbeitung von MySQL-Datenbanken und die Administration von
MySQL-Datenbankservern
Die Startseite der MySQL-Workbench bietet den Einstieg zu allen Funktionen der Workbench
Im linken Bereich der Startseite können mit den drei Tabulatoren „MySQL Connections“, „Model“ und „Migration“ die drei Kernbereiche „Server-Administration und
Datenbankverwaltung“, „Datenmodellierung“ und „Datenmigration“ ausgewählt werden
Wird eine Verbindung zum Server hergestellt, öffnet sich ein Reiter zur Server-Administration und Datenbank-verwaltung
Hier kann im Navigator-Fenster auf der linken Seite mit dem Reiter „Administration“ die Menüpunkte zur Server-Administration angezeigt werden
Im Navigator-Fenster auf der linken Seite kann mit dem Reiter „Schemas“ die vorhandenen Schemas (Daten-banken) mit ihren Tabellen, Views, Stored
Procedures und Funktionen angezeigt werden
Mit Rechtsklick im Schema-Bereich und dem Untermenü-punkt „Create Schema...“ kann ein neues Schema erstellt werden
Mit Rechtsklick auf ein Schema und dem Untermenüpunkt „ Alter Schema...“ kann ein Schema geändert und mit „Drop Schema...“
gelöscht werden
Mit Rechtsklick auf den Unterpunkt „Tables“ eines Schemas und dem Untermenüpunkt „Create Table...“ kann eine neue Tabelle erstellt werden
Mit Rechtsklick auf eine Tabelle und dem Untermenüpunkt „Alter Table...“ kann eine Tabelle geändert, mit „Truncate Table...“
geleert und mit „Drop Table...“ gelöscht werden
Mit Rechtsklick auf eine Tabelle und dem Untermenüpunkt „Select Rows – Limit 1000“ können die ersten 1000 Daten-sätze aus der Tabelle
angezeigt werden
Daten können in eine Tabelle eingefügt werden, indem mit dem Mauszeiger in die Felder mit „NULL“ geklickt und der entsprechende Wert eingegeben wird
Daten in einer Tabelle können gelöscht werden, indem die entsprechende(n) Zeile(n) markiert und mit Rechtsklick auf den markierten Bereich das Kontextmenü geöffnet
und hier der Punkt „Delete Row(s)“ gewählt wird