Relationale Datenbanken
Das relationale Datenbankmodell
Eine relationale Datenbank ist eine Datenbank, die auf dem tabellenbasierten relationalen Datenbankmodell basiert. Eine Relation ist eine mathematische Beschreibung einer Tabelle und besteht aus Attributen und Tupeln. Ein Attribut beschreibt dabei den Typ eines Attributwerts und wird auch als Feld bezeichnet. Ein Tupel ist eine Kombination aus bestimmten Attributen und wird auch als Datensatz bezeichnet. Die Attribute entsprechen in einer Tabelle den Spalten und die Tupel den Zeilen:

Beziehungen zwischen Relationen
Mit Hilfe von Verknüpfungen können in relationalen Datenbanken Beziehungen zwischen Tabellen definiert werden. So können z. B. in einem Bestellsystem Beziehungen zwischen Benutzern und Bestellungen hergestellt werden. Die Verknüpfungen erfolgen über eindeutig identifizierbare Felder, die auch als Schlüssel bezeichnet werden und die in beiden Tabellen enthalten sein müssen. Enthält eine Tabelle keine eindeutigen Felder, können als Schlüssel auch zusätzliche Felder mit ID‘s erstellt werden. Dabei können Beziehungen auch zwischen mehreren Tabellen bestehen:

Hinweis: Im relationalen Datenbankmodell werden sowohl die Zusammenstellungen von Attributen innerhalb von Tabellen als Relationen bezeichnet, als auch die Verknüpfungen zwischen Tabellen. Für die Beziehungen zwischen den Tabellen wird im Englischen aber in der Regel nicht das Wort „relation“ sondern das Wort „relationship“ verwendet!
Relationale Algebra
Die relationale Algebra definiert eine Menge von Operationen zur Manipulation von Relationen in relationalen Datenbanken. Theoretisch basieren alle Operationen in einer relationalen Datenbank auf der relationalen Algebra. Sie beschreibt die wesentlichen Operationen, mit denen Daten in Datenbanken gespeichert, abgefragt und manipuliert werden können. Alle komplexeren Operationen basieren auf den folgenden sechs Basisoperationen:
Selektion
Bei der Selektion wir mit Hilfe eines Vergleichsausdrucks (z. B. name = „Max“) festgelegt, welche Tupel (Datensätze) als Ergebnis zurückgegeben werden:

Projektion
Bei der Projektion werden einzelne Attribute (Spalten) aus der ursprünglichen Attributmenge extrahiert. Die Projektion entspricht somit einer Selektion auf Spaltenebene:

Kreuzprodukt
Das Kreuzprodukt (oder Kartesische Produkt) ist die Kombinationen aller Tupel (Datensätze) einer Relation (Tabelle) mit allen Tupeln einer anderen Relation:

Vereinigung
Bei der Vereinigung werden alle Tupel einer Relation und alle Tupel einer anderen Relation zu einer einzigen Relation vereint. Doppelt vorkommende Tupel werden nur einmal dargestellt. Voraussetzung für die Vereinigung ist, dass alle Relationen das selbe Relationenschema haben, d. h. die selben Attribute und Attributtypen:

Differenz
Bei der Differenz werden aus der ersten Relation alle Tupel entfernt, die auch in der zweiten Relation vorhanden sind. Auch hier ist Voraussetzung, dass die Relationen das selbe Relationenschema haben, d. h. die selben Attribute und Attributtypen:

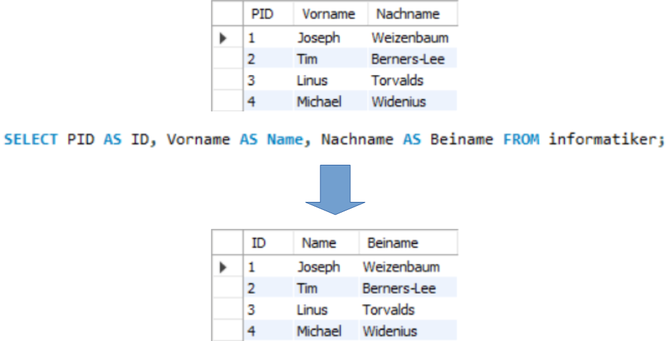
Umbenennung
Bei der Umbenennung können Attribute und Relationen umbenannt werden. Mit Hilfe der Umbenennung können auch Kreuzprodukte bei gleichen Attributnamen sowie Vereinigungen und Differenzen bei unterschiedlichen Attributnamen gebildet werden: